Pascal VOC
11.5K images organized in 20 classes. Also contains bounding boxe anotation and segmentation mask
Visual object challenge conducted between 2006 - 20012.
Image net :
Dataset containing 14M images organized into 22K categories.
ImageNet classification Challenge (starting 2009) : Test set containing 1000 object classes, 1431167 images. Algorithm should produce the correct label in top 5 predictions for a sample to be evaluated as a success. In 2015, REsNET achieved a error rate of 3.57% which was lesser than Human error rate 5.1%
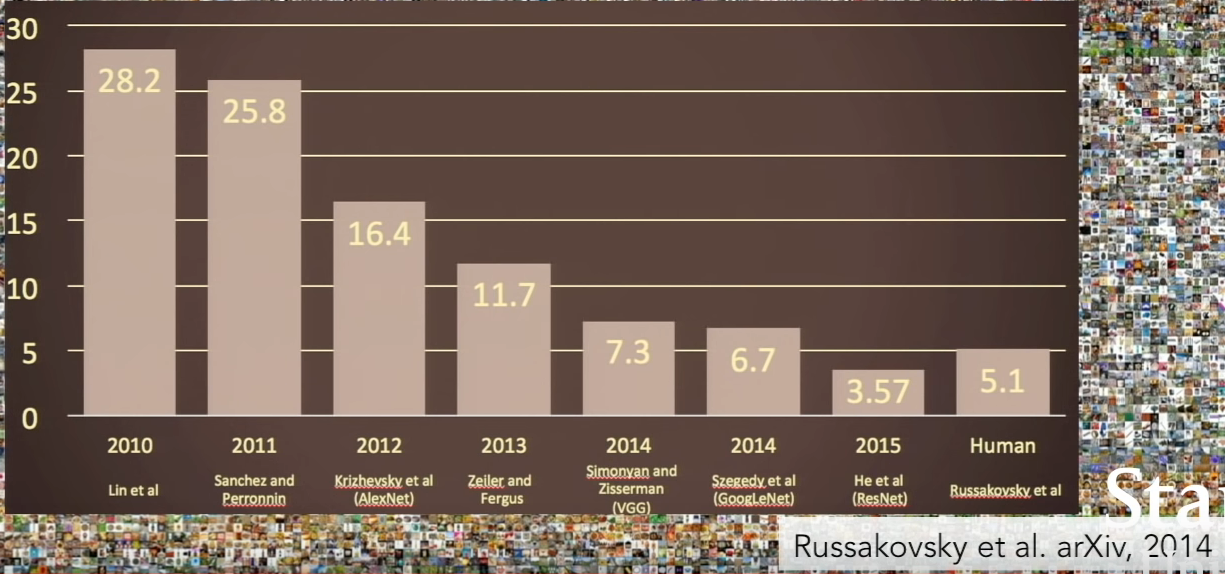
Notice the drop in error rate in 2012. This was the CNN model - AlexNet, which gave impetus for using CNNs. However, the first CNN model used for computer vision task was developed in 1998 by Yann LeCun's group which was used for digit classification (This dataset was called MNIST and it became the hello world problem of computer vision). The reason for this success to be truely realized only in 2012 was because of key advents in computational speed with the arrival of GPUs. Another reason was the availablity of large labelled datasets.
But Object Classification is just a first level problem. We then moved on to Object detection and Semantic segmentation. The holy grail of computer vision is to understand the image (or sequence of images) a.k.a understanding the scene
Hello world dataset for image classification
CIFAR10 : 10 classes, 60K images (32x32 pixels, 3 Channels)