Semantic segmentation¶
We assign a category label to every pixel in an image. Therefore, loss is incurred at every pixel
Input image : CxHxW, where C is the number of channels
Output Image : KxHxW, where K is the number of categories
Fully convolutional architecture¶
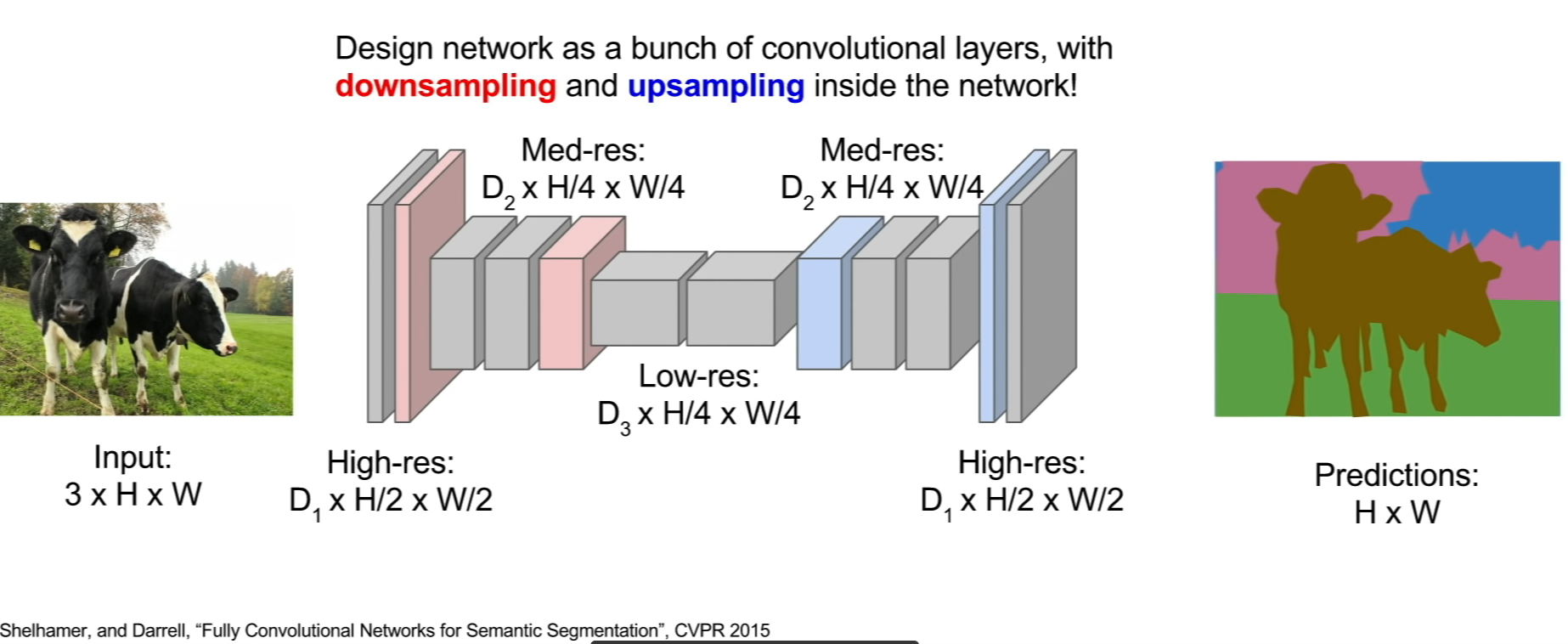
Upsampling¶
Upsampling can be done by transpose convolutions. The use of word transpose becomes clear when we look at convolution operation as circulant matrix multiplication operation

![]()
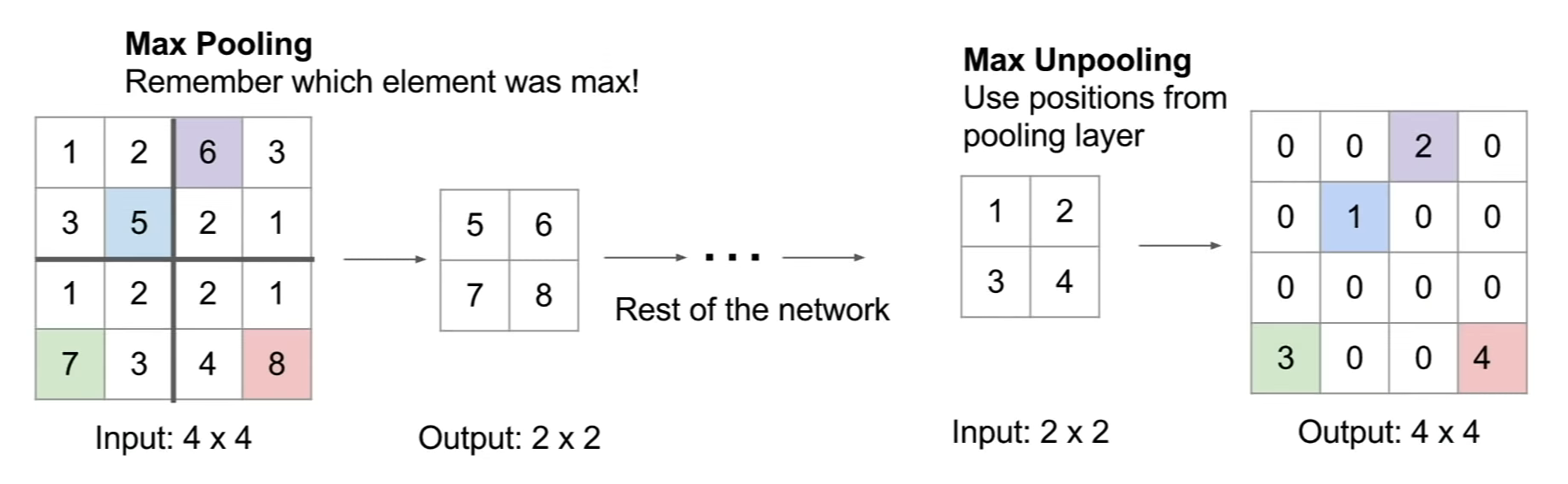
max-unpooling operation
Instance segmentation¶
Object detection + Semantic segmentation
Need mask proposals from image.
Mask RCNN is built on top of Faster RCNN, where bounding box coordinates go through bilinear pooling to extract the region and pixel wise classification is done