tf.data API¶
This pipeline is used for fast reading and processing of input data
Guidelines:¶
1) from_generator: When you want to use libs outside tensorflow for preprocessing (sklearn,numpy). Recommended for processing json, xml, csv datafiles which are not usually too large. Also make sure that the generator function is implemented in deployment code
2) from_tensor_slices: When each data is present in separate file and you want to benefit from parallelization in the I/O step
3) TextLineData : When a data element represents a line of text files
4) Make CSV dataset: Tensflow pipeline for CSV data. USe if you dont need sklearn/numpy pre processing
5) FixedLengthRecordDataset: When data is in a binary file and each sample is of fixed number of bytes
import tensorflow as tf
import numpy as np
import pandas as pd
import glob
from PIL import Image
import matplotlib.pyplot as plt
%matplotlib inline
files_path = "datasets/VOC2007/JPEGImages/*.jpg"
filesname = glob.glob(files_path)
print(len(filesname))
1) Using generator¶
Easy to link python coded preprocessing.
The generator function returning np array is passed on to the Datasets API
#I still prefer tensorflow preprocessing, as it helps me control device placements
def process_image(im):
with tf.device('/cpu:0'):
image_tensor = tf.convert_to_tensor(im)
float_image_tensor = tf.image.convert_image_dtype(image_tensor,tf.float32)
#resize requires size to be knwown before hand, so we use it as part of generator.
float_resized_image = tf.image.resize_images(float_image_tensor,(224,224))
uint_resized_image = tf.image.convert_image_dtype(float_resized_image,tf.uint8)
return uint_resized_image
def generate_images():
#Do not use MUTABLE global variables inside generator
#filesname is immutable
for f in filesname:
print("Fetching ", f)
#It is not a bad idea to nest sessions here, as this will run in a separate thread
yield tf.Session(config=tf.ConfigProto(log_device_placement=True)).run(process_image(Image.open(f)))
As much as possible,put all the data processing pipeline on the CPU to make sure that the GPU is only used for training the deep neural network model
for im in generate_images():
x = im
break
Image.fromarray(x)

tf.data.Dataset.from_generator
ds = tf.data.Dataset.from_generator(generate_images,tf.uint8,(224,224,3))
Shuffling buffer stores BUFFERSIZE elements in the buffer and randomly selects from them. Once the element is selected, it pushes the next element in the dataset into the buffer
BUFFERSIZE = 30 #Better to close to data size
NUM_EPOCHS = 10
ds = ds.shuffle(BUFFERSIZE)
ds = ds.repeat(NUM_EPOCHS)
Vectorize cheap user-defined functions passed in to the map transformation to amortize the overhead associated with scheduling and executing the function.
Parallelize the map transformation by setting the num_parallel_calls argument. We recommend using the number of available CPU cores for its value.
Note: We use the resize preprocessing as a part of generator, because it requires the size of image to be known before hand. It also falls under the I/O (Yellow) region in the image below
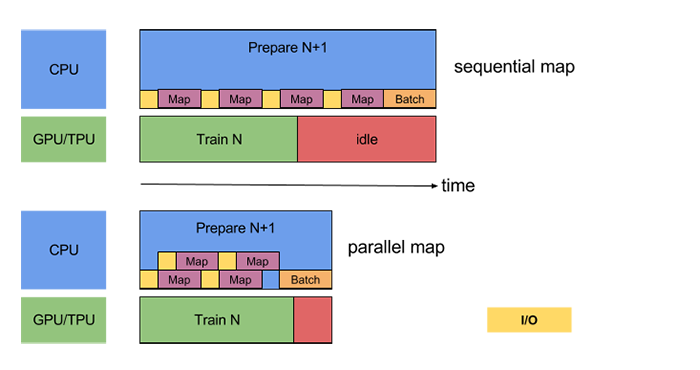
ds = ds.map(lambda x: tf.image.random_flip_left_right(x,seed=101),num_parallel_calls=2)
ds = ds.map(lambda x: tf.image.random_saturation(x,lower=0.2, upper=1.8),num_parallel_calls=2)
If you are combining pre-processed elements into a batch using the batch transformation, we recommend using the fused map_and_batch transformation; especially if you are using large batch sizes. (Although now we use them separately)
ds = ds.batch(10)
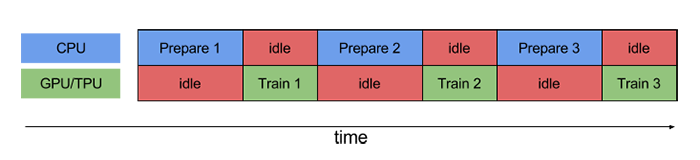
Prefetching is a technique used by computer processors to boost execution performance by fetching instructions or data from their original storage in slower memory to a faster local memory before it is actually needed
Use the prefetch transformation to overlap the work of a producer and consumer. In particular, we recommend adding prefetch(n) (where n is the number of elements / batches consumed by a training step) to the end of your input pipeline to overlap the transformations performed on the CPU with the training done on the accelerator.
WITHOUT PREFETCHING
WITH PREFETCHING
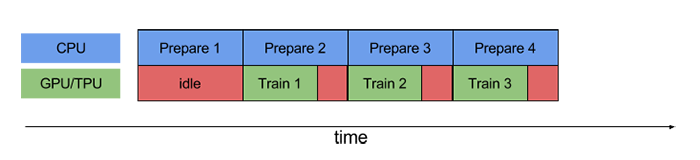
ds = ds.prefetch(1) #Max Number of batches that ll be prefetched, here just get next batch
iterator = ds.make_one_shot_iterator()
im_batch = iterator.get_next()
im_batch
sess = tf.Session()
out = sess.run(im_batch)
prefetches 2 batches,fills shuffling buffer, but outputs only the required
out.shape
Image.fromarray(out[0])

Image.fromarray(out[1])

out = sess.run(im_batch)
Image.fromarray(out[0])

Image.fromarray(out[1])

2) Using from_tensor_slices¶
from_tensor_slices creates a dataset with a separate element for each row of the input tensor (here filesname list is automatically casted to tensor)
The resulting dataset consist of sequence of string tensor
The further operations are done on a tenser. Hence, we are expected to restrict to the tensorflow methods
filesname[:5]
dataset = tf.data.Dataset.from_tensor_slices(filesname)
def read_jpg(filename):
#filename is a string tensor. So tensorflow libs are expected to be used
image_string = tf.read_file(filename)
image = tf.image.decode_jpeg(image_string, channels=3)
return image
def resize_img(image_tensor):
float_image_tensor = tf.image.convert_image_dtype(image_tensor,tf.float32)
float_resized_image = tf.image.resize_images(float_image_tensor,(224,224))
uint_resized_image = tf.image.convert_image_dtype(float_resized_image,tf.uint8)
return uint_resized_image
dataset = dataset.map(read_jpg, num_parallel_calls=4)
dataset = dataset.map(resize_img,num_parallel_calls=4)
dataset = dataset.batch(100)
dataset = dataset.prefetch(1)
iterator = dataset.make_one_shot_iterator()
im_batch = iterator.get_next()
out = sess.run(im_batch)
out.shape
Image.fromarray(out[1])

3) When each line of your file is a data¶
dataset = tf.data.TextLineDataset("files/data_csv.csv")
dataset = dataset.map(lambda x: tf.string_split([x],delimiter=',').values)
iterator = dataset.make_one_shot_iterator()
next_el = iterator.get_next()
sess.run(next_el)
sess.run(next_el)
Zipping data from multiple files
features = tf.data.TextLineDataset("files/features.txt")
labels = tf.data.TextLineDataset("files/labels.txt")
dataset = tf.data.Dataset.zip((features,labels))
#def func(x,y):
# ...
dataset = dataset.map(
lambda x,y: (tf.multiply(tf.string_to_number(x,tf.float32), 2.0),tf.string_to_number(y,tf.int32)))
iterator = dataset.make_one_shot_iterator()
next_el = iterator.get_next()
sess.run(next_el)
sess.run(next_el)
4) Make CSV dataset¶
Use this only when data is large and you can exploit from parallelization, otherwise use generator
dataset = tf.data.experimental.make_csv_dataset("files/pima-indians-diabetes.csv",batch_size=3)
def map_f(x):
print(x)
return x
dataset = dataset.map(map_f)
dataset = dataset.prefetch(1)
iterator = dataset.make_one_shot_iterator()
next_el = iterator.get_next()
sess.run(next_el)
next_el['BMI'],next_el['Group']
sess.run([next_el['BMI'],next_el['Group']])
5) Reading FixedLengthRecords from binary file¶
We ll illustrate this example with MNIST dataset. The format of the data is described in the official webpage
Considering the training set binary file,
first 4 bytes : Represents meta information
Remaining bytes: There after, each byte (2^8) represents 1 pixel. 60000 images are represented in 60000x28x28 bytes
Check the file with numpy¶
Opening binary file
from pathlib import Path
p = Path('./datasets/MNIST_data/')
pt = p / 'train-images.idx3-ubyte'
ft = pt.open('rb')
Read the first 4 bytes in big endien format
ft = pt.open('rb')
dt = np.dtype('u4') # 'u4' is int32
dt = dt.newbyteorder('>') #'>' represents big engien
magic,size,h,w = np.frombuffer(ft.read(4*4),dt)
magic,size,h,w
Read the remaining bytes
data = np.frombuffer(ft.read(),'u1')
data.shape
Each pixel is 1 byte
data = data.reshape(size,h,w,1)
data.shape
Tensorflow pipeline with FixedLengthRecord¶
Records can either be a single file or even a set of files. Only the number of bytes per sample matters
#Read records of 28x28 after a offset of 16 bytes
dataset = tf.data.FixedLengthRecordDataset(['datasets/MNIST_data/train-images.idx3-ubyte'],28*28,header_bytes=16)
Decode byte string
dataset = dataset.map(lambda x: tf.decode_raw(x,tf.uint8,little_endian=False))
#actually little or big endien does not matter here. there is only one byte
Reshape
dataset = dataset.map(lambda x: tf.reshape(x,(28,28)))
Batch
dataset = dataset.batch(10)
Load
iterator = dataset.make_one_shot_iterator()
next_el = iterator.get_next()
sess = tf.Session()
o = sess.run(next_el)
o.shape
Image.fromarray(o[0])

Image.fromarray(o[9])

Using Iterators with multiple dataset¶
We will always have different reading pipeline for training, validation and production. To handle such cases, use reinitializable iterators
This type of iterators are useful when we want to fine tune a trained model on different dataset with different preprocessing pipeline
For reinitializable iterators, the output shapes and output types should be same for all datasets (But Batch sizes can be different)
#Training
training_dataset = tf.data.Dataset.range(100)
training_dataset = training_dataset.map(lambda x: tf.cast(x,tf.int32))
training_dataset = training_dataset.map(lambda x: x + tf.random_uniform([],-10,10,dtype=tf.int32))
training_dataset = training_dataset.batch(5)
#Validation/Test
validation_dataset = tf.data.Dataset.range(50)
validation_dataset = validation_dataset.map(lambda x: tf.cast(x,tf.int32))
validation_dataset = validation_dataset.batch(1) #Can be different batch size
#Serving
production_input = tf.placeholder(tf.int32,[])
production = tf.data.Dataset.from_tensors(production_input) #use tensor_slices to enable batching
production = production.batch(1)
training_dataset.output_shapes,validation_dataset.output_shapes,production.output_shapes
#We could use the `output_types` and `output_shapes` properties of either of the datasets
iterator = tf.data.Iterator.from_structure(training_dataset.output_types,training_dataset.output_shapes)
next_el = iterator.get_next()
next_el
#Create initializers
training_init_op = iterator.make_initializer(training_dataset)
validation_init_op = iterator.make_initializer(validation_dataset)
production_init_op = iterator.make_initializer(production)
with tf.Session() as sess:
#Training
sess.run(training_init_op)
print(sess.run(next_el))
print(sess.run(next_el))
#Validation/Test
sess.run(validation_init_op)
print(sess.run(next_el))
print(sess.run(next_el))
#Serving
#Make sure that the input type and shape is compatable with the pipeline
sess.run(production_init_op,{production_input:np.asarray(18,np.int32)})
print(sess.run(next_el))
sess.run(production_init_op,{production_input:np.asarray(20,np.int32)})
print(sess.run(next_el))
NOTE: If you dont want to reuse preprocessing code, you can completely eliminate dataset pipeline for Serving by having condition check inside the graph